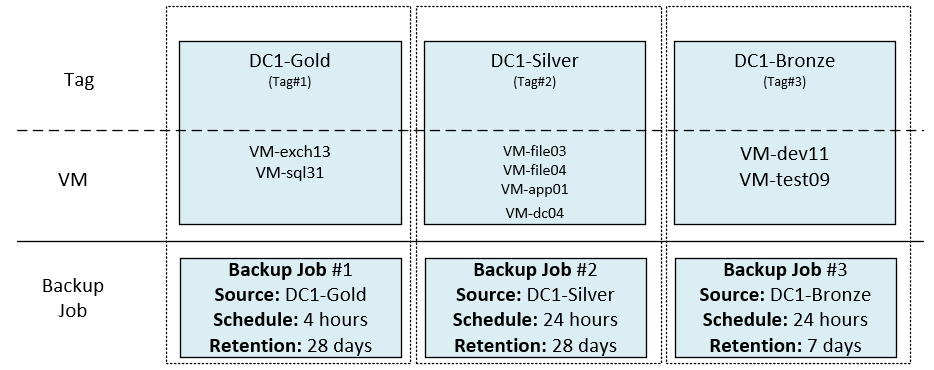
Tags are a great way to manage and organise resources across a vSphere environment, with tags we can sort and group VMs together based on any criteria we wish. Veeam can even leverage these “groups of VMs” in many different ways.
For example, Veeam Disaster Recovery Orchestrator leverages tags for orchestration plans and to make sure VMs are restored to the right place with tag-based recovery locations.
Veeam ONE Business View can automatically create and assign tags to VMs based on any desired criteria with its categorization engine, this is on top of VeeamONEs capability to run reports based on tags. I’ve previously written about Veeam ONE Business View which can be found here.
Veeam Backup & Replication (VBR) also can utilise tags for any job. By simply adding tags as the source object to the job, VBR will protect any VMs with that same tag, this can be especially time-saving if VMs are frequently being provisioned. Another benefit of tags is that, unlike folders and resource pools, VMs can be assigned multiple tags.
Let’s take a look at how we could group a selection of 8 VMs into various different backup jobs using tags.