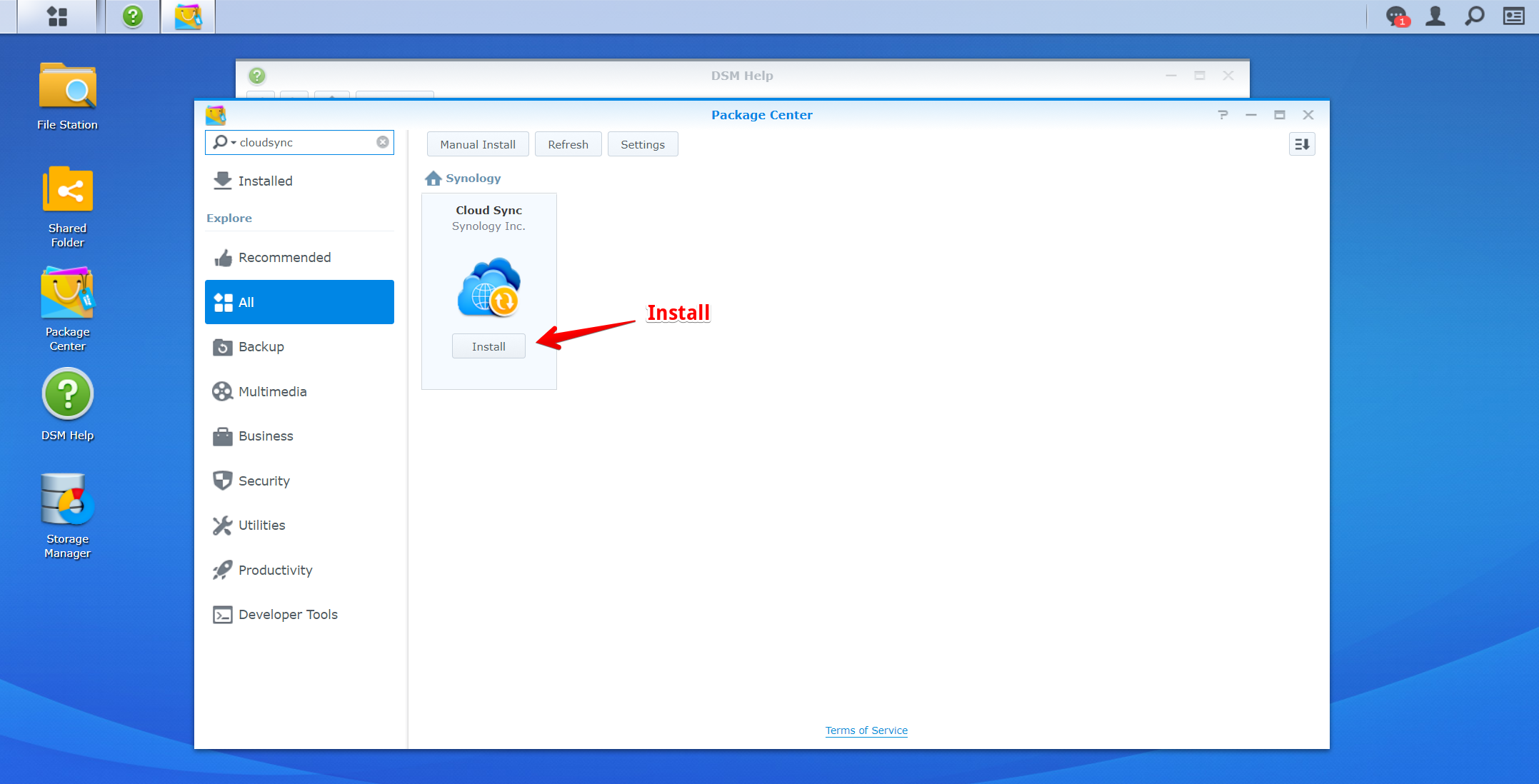
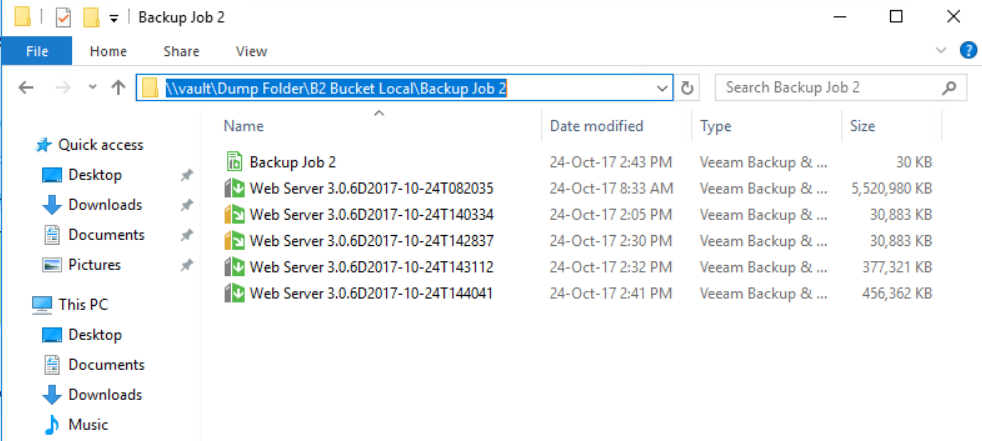
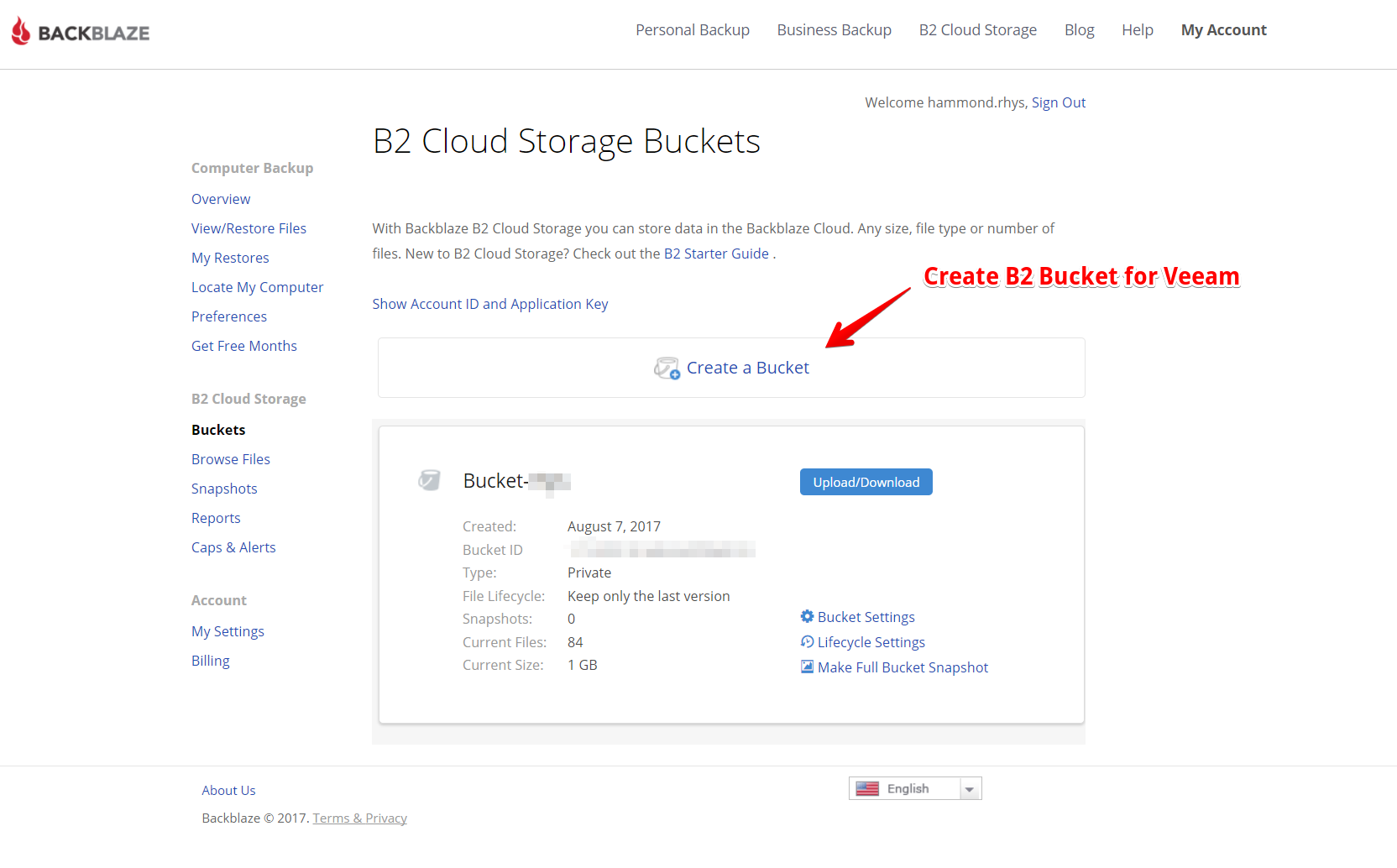
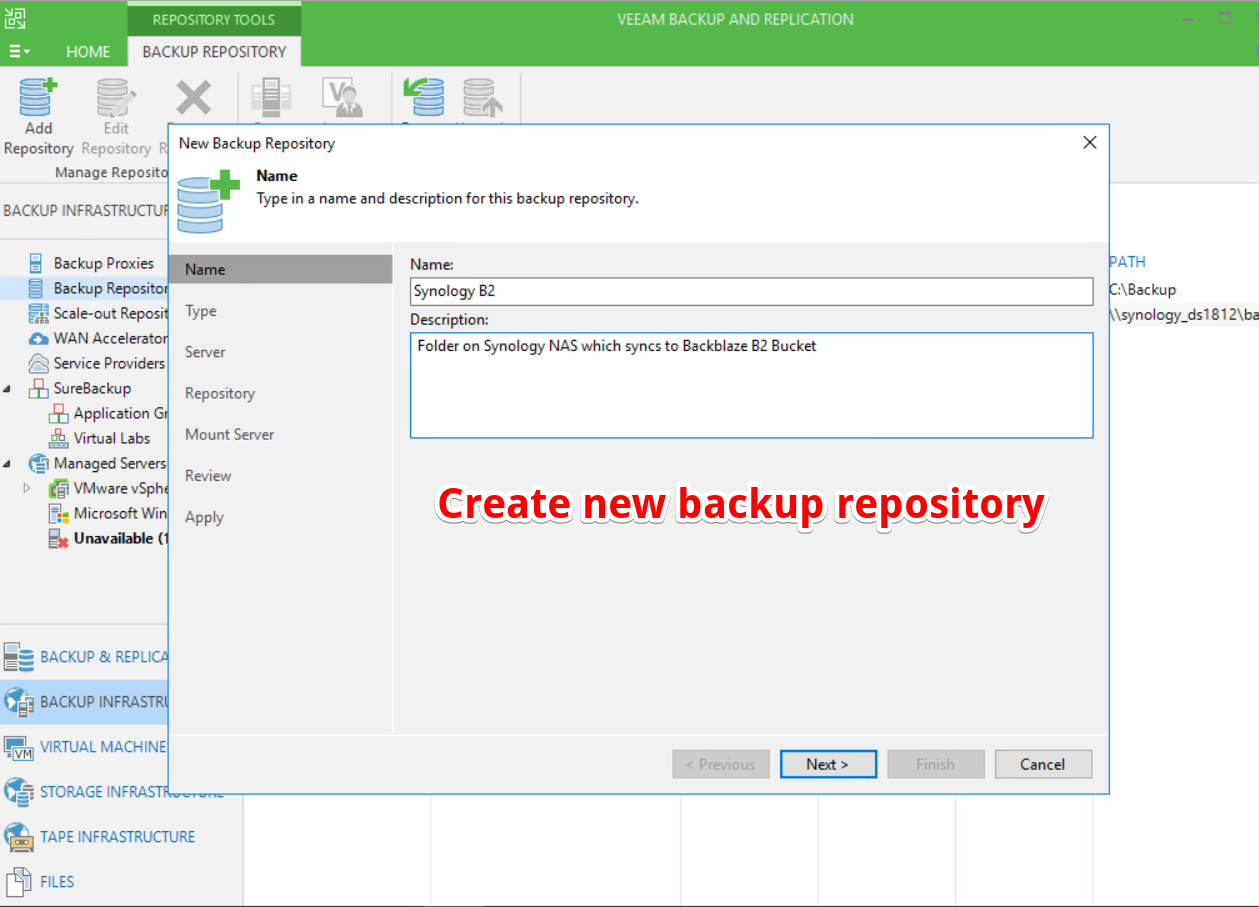
Sending Veeam backups to object storage such as Azure Blob has become a hot topic in the last few years. According to Veeam’s quarterly report for the end of 2021, Veeam customers moved over 500 PB of backups just into the top 3 cloud object storage vendors alone.
With many organisations starting to dip their Veeam toes into object storage I thought I would write a bit more about the subject. This blog post is aimed at helping backup administrators who wish to better understand from a Veeam perspective working with public cloud object storage, specifically Azure Blob.
Compared to the traditional NAS or disk-based block storage Object Storage is a completely different shift in how data is stored and accessed. For example, in object storage, it’s intended that files are not modified. In fact, there is no way to modify part of an object’s data and any change requires deletion and replacement of the whole object.
In Azure terminology, objects are stored in a ‘Blob’, which can be thought of as similar to a volume on a disk but far more scalable. Blob storage is a pay-per-use service. Charges are monthly for the amount of data stored, accessing that data, and in the case of cool and archive tiers, a minimum required retention period. In case you haven’t realised, Blob storage is Microsoft’s object storage solution.
There are numerous methods we can utilise to leverage Microsoft Azure Blob with Veeam Backup & Replication. For example, Azure Blob can be used as an Archive Tier target within a SOBR (Scale-Out Backup Repository) for long-term retention of backups, an archive repository for Veeam NAS Backups and some readers may even be familiar with the external repositories function.
The most popular method is using Blob as a Veeam Capacity Tier which is configurable within a Veeam Scale-Out Backup Repository.