What happened to Archive Tier?
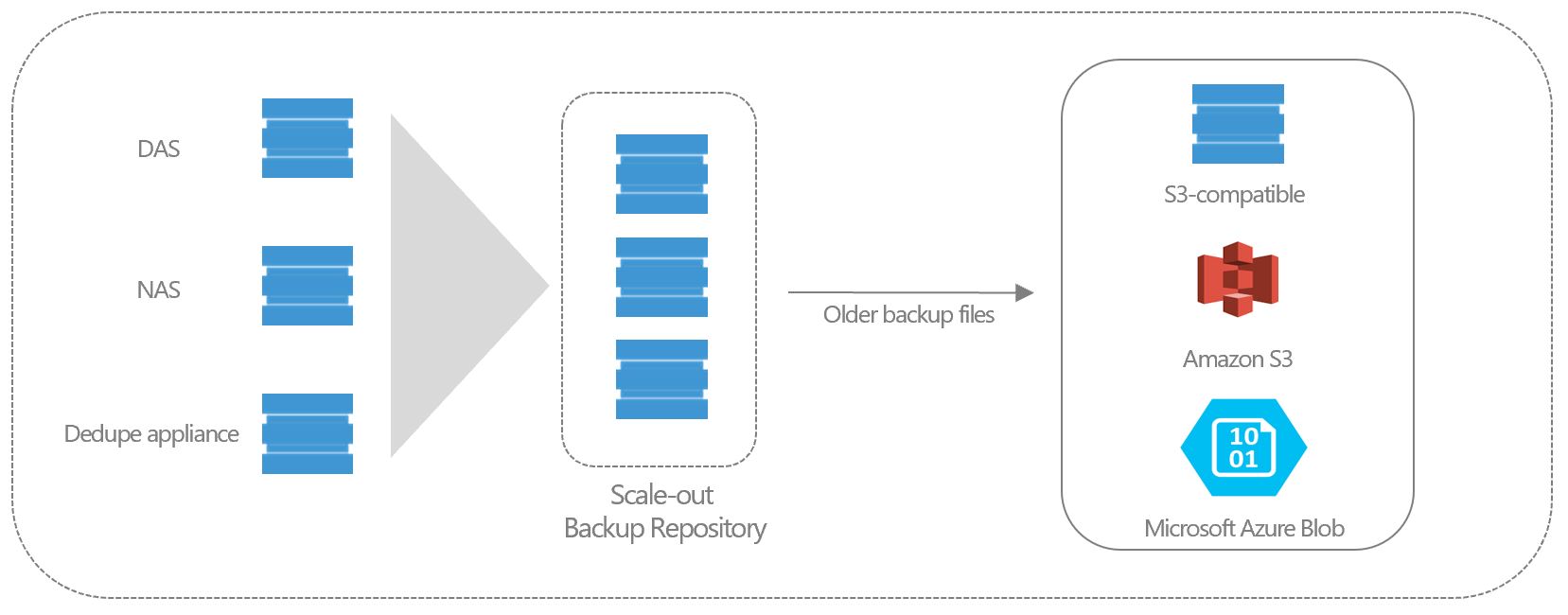
Archive Tier was announced back at VeeamON 2017 New Orleans alongside a raft of new features scheduled for release with Veeam Backup & Replication v10. Archive Tier would enable Veeam administrators to easily add regular disk-based backup repositories, object-based storage repositories or even tape as an archive extent to a SOBR (Scale-Out Backup Repository) which could then be configured to copy any backup or move sealed backup files from the SOBR across to said archive extent.
The ability to archive backup files to a particular archive extent such as tape or cheaper disk was a great addition, but the significant improvement was the native integration with object storage which has been a highly requested feature for several years now. During VeeamON it was announced that AWS S3, AWS Glacier, Azure BLOB and Swift compatible object storage to be supported.
This is fantastic! Bye bye storsimple! #veeamon pic.twitter.com/StVYIxnd7F
— Rhys Hammond (@HammondRhys) May 17, 2017
Copying Veeam backup files to object storage has always been possible through the use of third-party vendor storage gateways, such as the AWS Storage Gateway or Azure StoreSimple but speaking from my own experiences, these tools don’t always deliver what they promise and require additional skills to support.
The upcoming Veeam Archive Tier looked very promising, but it had its limitations though,
- Each backup file would need to be copied in its entirety to the archive tier, resulting in less than ideal storage consumption especially with regular full backup files
- Restoring even a small file would require pulling the entire backup file back down onto a local repository (that has sufficient free space) resulting in lengthy restore operations and high egress charges
- Significant bandwidth requirements to handle the backup data movement
Veeam RnD understood a better solution was possible which would significantly reduce these limitations. The hard work Veeam has put in has now accumulated into the recently announced successor to Archive Tier, which is called Cloud Tier.
Cloud Tier – What is it
So Veeam went back to the drawing boards and completely re-engineered Archive Tier from the ground up. The idea is similar, you still have the native integration with object storage such as Azure BLOB, AWS S3 or on-prem object storage but it’s less of an archive solution and more of a tiering solution, hence the new name Cloud Tier.
It’s worth mentioning that Cloud Tier is the marketing name, but in the UI it will be called Capacity Tier. It won’t be available in Veeam Standard edition, only Enterprise and Enterprise Plus.
Some of the most significant changes from Archive Tier is the new way in which Veeam will manage backup data written into the Capacity Tier (object storage). For starters, Veeam will create metadata for each backup file tiered, by separating metadata from blocks and building a dehydration index Veeam can track what blocks have already been moved thus avoid writing duplicate blocks twice. This results in not only significant storage consumption savings but a substantial increase in performance.
After backup files off-load into the Capacity Tier, a “shell” of their former state remains with the newly created metadata; this metadata contains the pointers to contents stored in object storage. What’s impressive is that all Veeam restore functionality will still work transparently with these shells including Instant recovery (including instant virtualisation of physical computer backups), entire computer and disk-level restore (including to different platforms) and file-level and item-level restore.
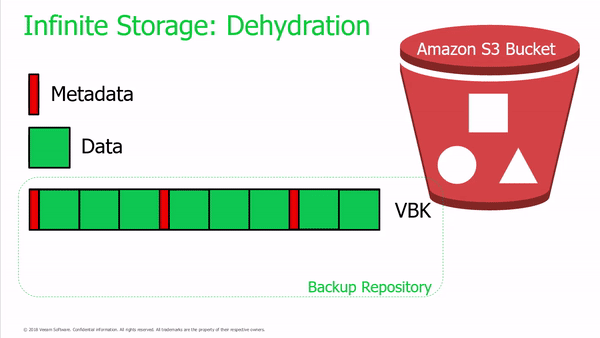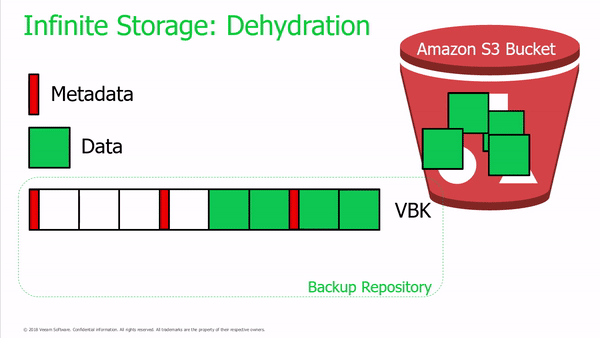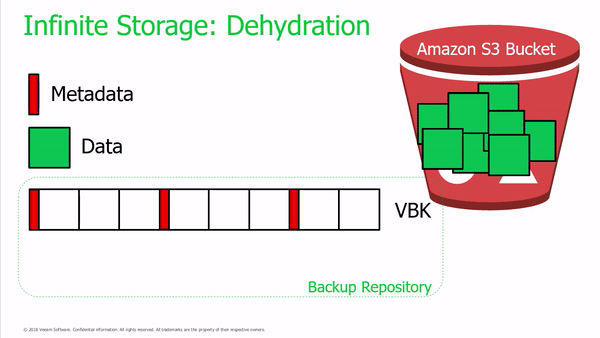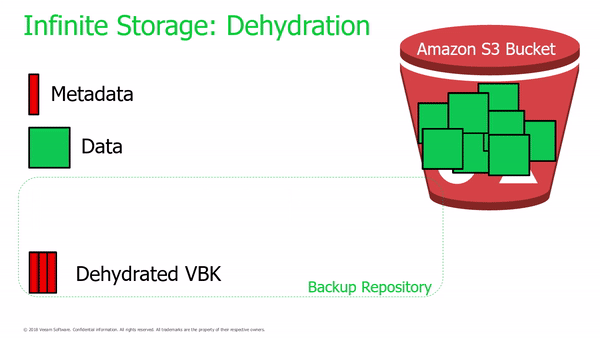
Importantly, Veeam administrators can still recover backups offloaded to object storage even when the local shells are lost. Veeam will prompt the Administrator if they would like to re-import when adding the previously created Capacity Tier.
In addition to these shells serving as pointers to the offloaded backup data, they also act as local “cache” to reduce cloud I/O charges Reducing cloud I/O charges is a significant improvement over the previous Archive Tier, with Veeam leveraging Intelligent Block Recovery to enable restoration of data using the oldest non-offloaded restore point to source data blocks from which are unchanged between the two points resulting in improved efficiency and speed of restore functions, and a reduction in egress charges.
In other words, when restoring from a backup file tiered into object storage, Veeam will automatically source as much information from the closest restore point stored locally before retrieving unique data blocks tiered into object storage. This process will dramatically reduce object storage egress when restoring from recently offloaded restore points while also improving restore performance.
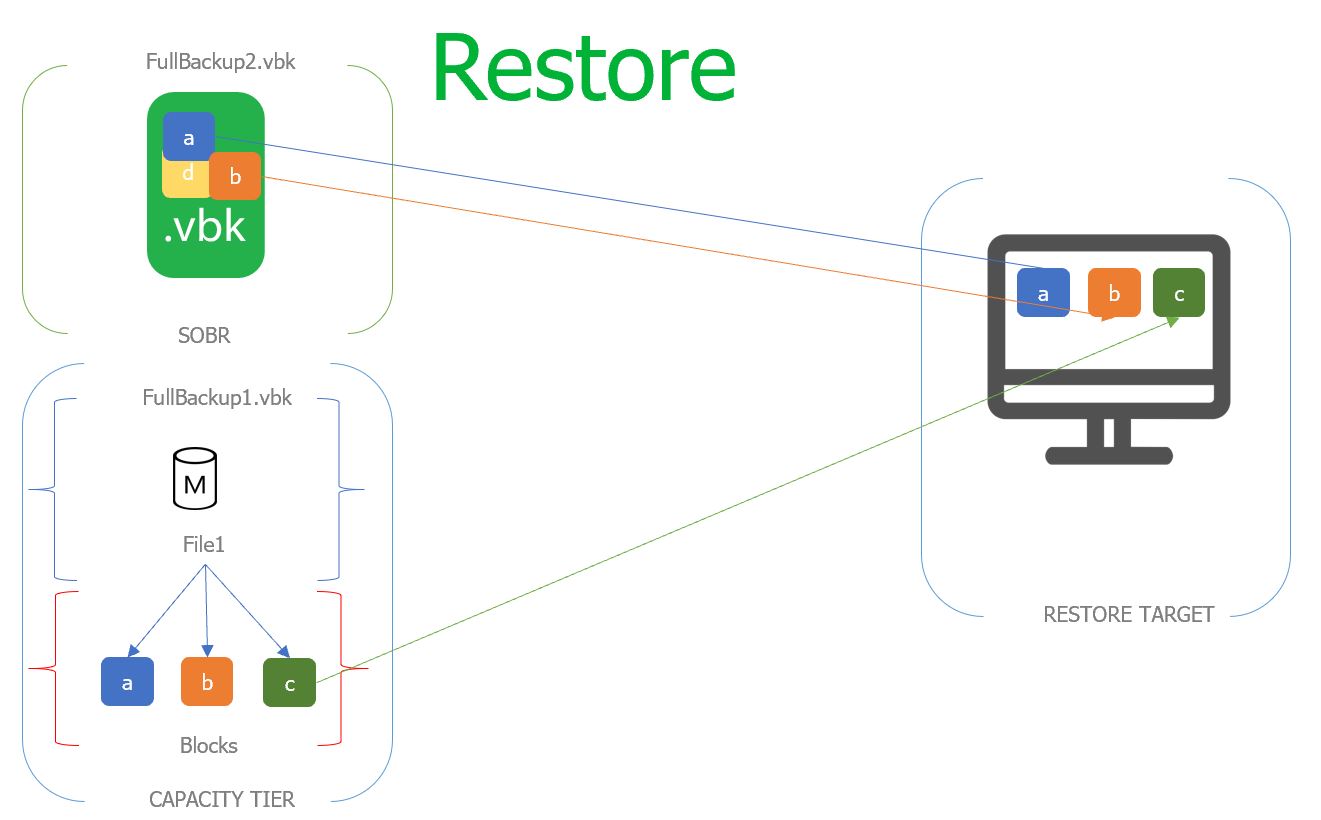
Unlike Archive Tier which could be configured to copy backup files, Capacity Tier will only move unique data blocks into object storage leaving behind the ‘shell’ file. Meaning you won’t be able to meet 3-2-1 backup by only relying on Capacity Tier since you’re not storing multiple copies of the backup data.
Operational restore windows are configurable values set in each SOBR which enables Administrators to define how old backup data needs to be before Veeam offloads it to the Capacity Tier. Setting this value to 0 days would result in backup files moved straight away if they are sealed.
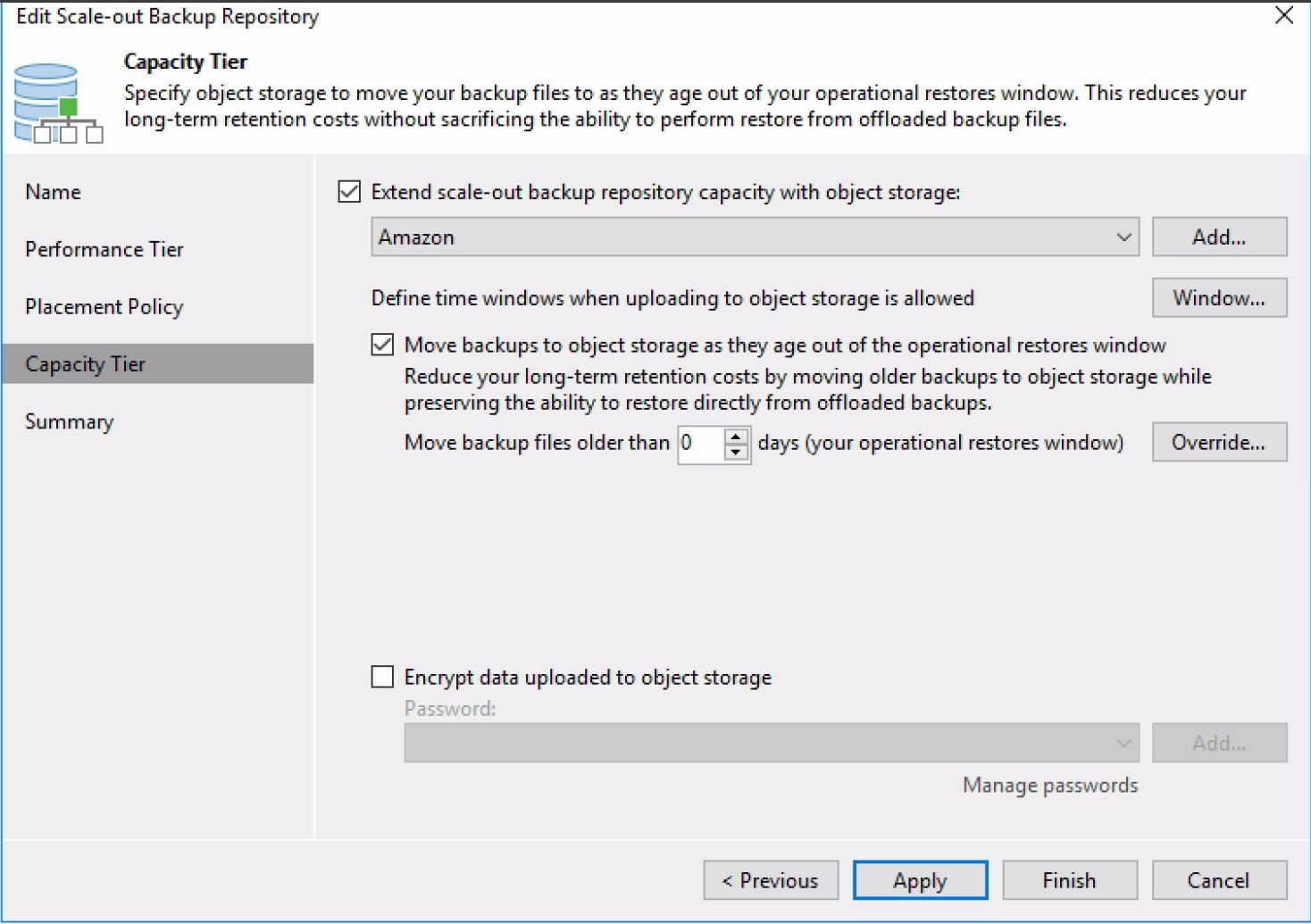
It’s possible to manually start the tiering of aged/sealed backups, there are three methods
i) While holding down ‘ctrl’ right-click on the SOBR, an option to “Run Tiering Job Now” will appear.
ii) A PowerShell Command can be run to achieve the same result
Start-VBRCapacityTierSync -Repository SOBRNAME
iii) In the inventory pane, open Backups, right-click a backup job and select properties. Find a candidate backup file and click ‘Move to capacity tier’. 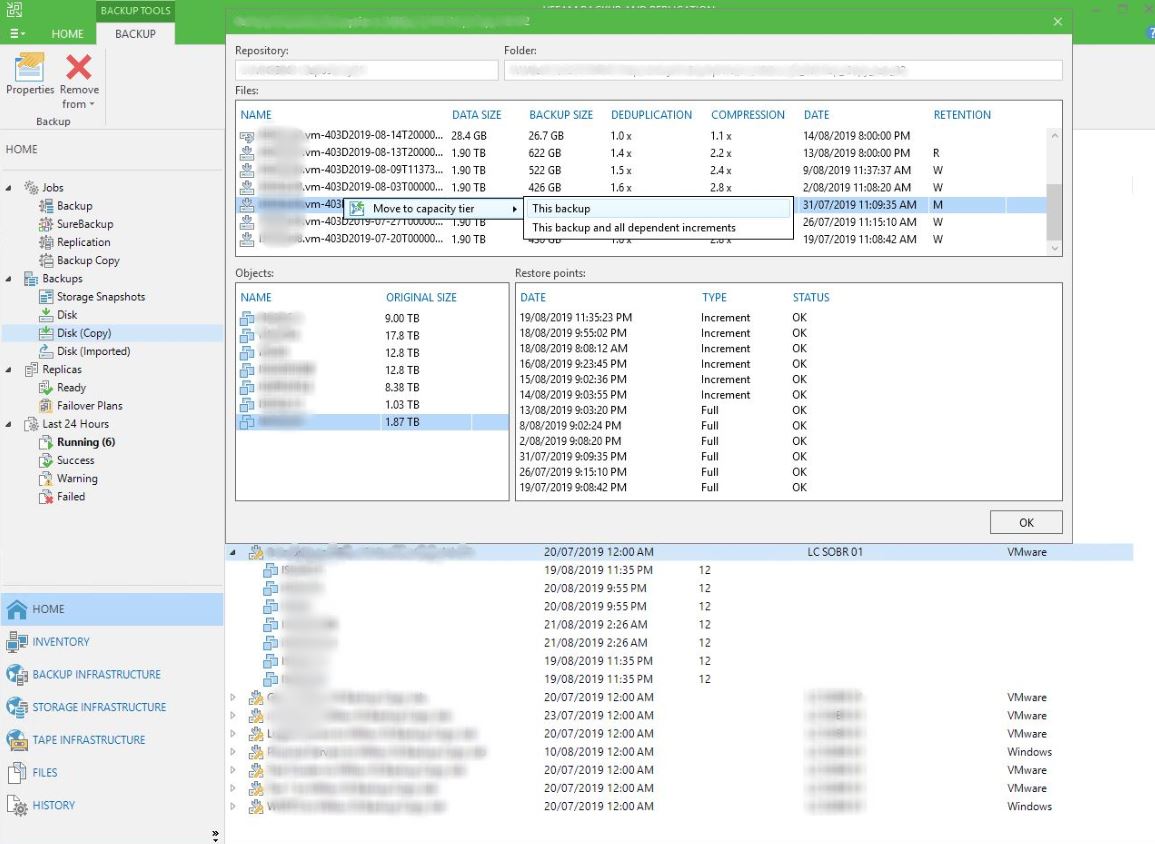
A sealed backup chain?
Sealed backup chains are backup points don’t require transformation. For Backup Copy Jobs it will be the GFS full backups that have been created. Not the ‘simple retention policy’ chain.

For regular backup jobs, Veeam considers the following as sealed.
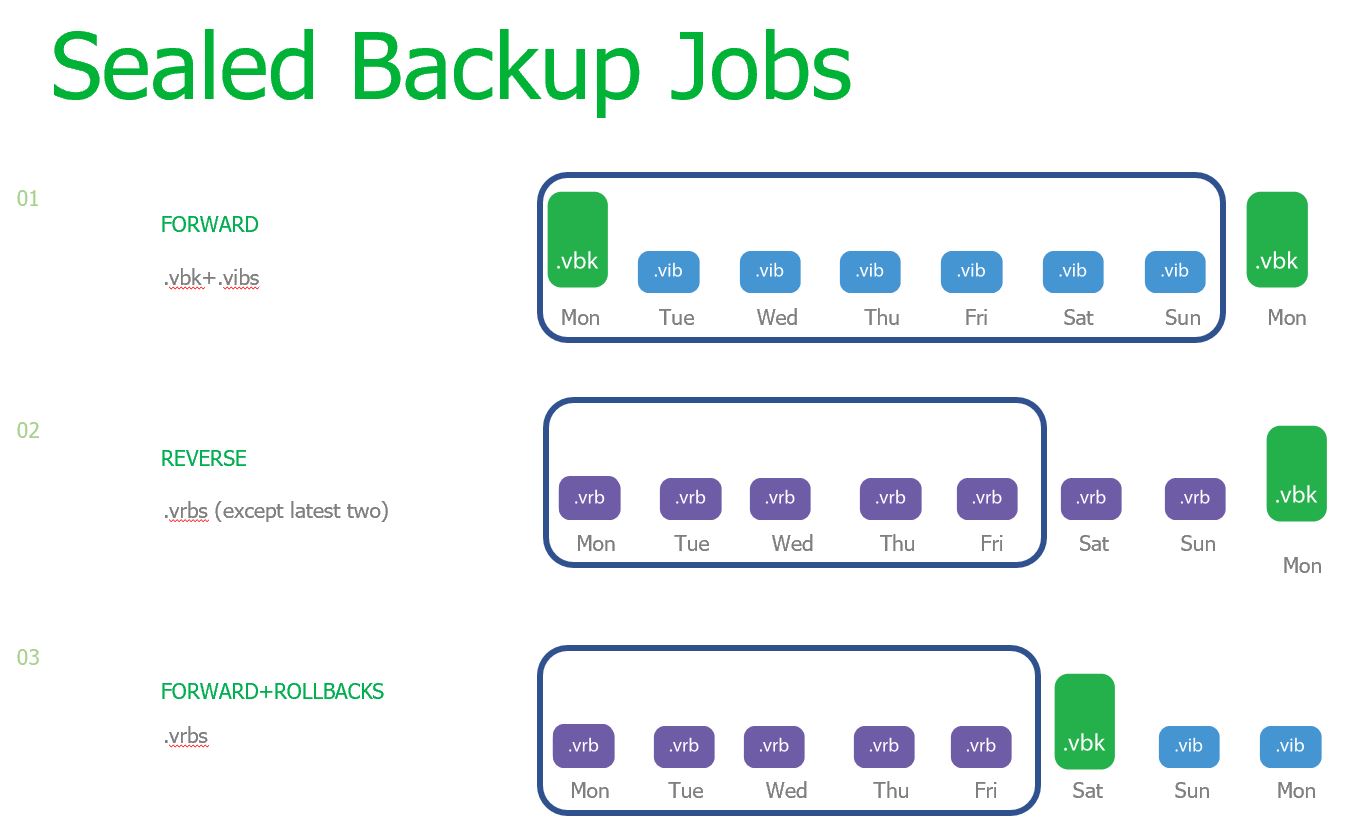
Consider a full backup file that has aged past the defined operational restore window but there are still incremental backup files dependent on this full, if the incremental files have not aged past the operational restore window then the full backup file cannot be tiered otherwise the chain would break. To prevent breaking a chain, Veeam will validate the backup chain state to ensure that any restore points to be offloaded belong to an inactive backup chain. A chain is considered inactive once there are no more incremental backups to be created in the chain, this is accomplished with a new Active Full (or Synthetic Full) backup file being created.
Remember that sealing a backup chain isn’t performed by some special process or operation though, it’s just the term to refer to a backup file which no longer needs to be modified.
What isn’t Cloud Tier?
Besides adding additional capacity to your SOBR by utilising cheaper object storage, Veeam Capacity Tier won’t replace your existing offsite backup strategy. Meaning you will still need to create copies of your backups to another backup repository just as before to meet the best practice of 3-2-1.
Remember that Veeam Cloud Tier will ‘move’ the backup file to object store (only write the unique blocks and leave behind a ‘shell’ file) therefore you are not creating another copy of the restore point. Secondly, only restore points that have aged past your defined operational restore window and sealed will be eligible to be offloaded into the Capacity Tier.
Anton Gostev has mentioned in the Veeam Forums that Veeam is considering adding a copy function to Cloud Tier in future updates, though you will still need a regular repository for the Performance Tier in the SOBR for all the reasons mentioned above. A Capacity Tier with the option to duplicate any created backups into object storage as soon as they are created (as opposed to moving them there as they age out of the operational restores window) would be very beneficial for Veeam Administrators.
Summary
Cloud Tier is Veeams take on hierarchical storage management, merely put Veeam will automatically move data from high-cost (Performance Tier) to low-cost (Capacity Tier) storage media. The data being moved is, of course, your backup files.
Cloud Tier has been designed to offload restore points that reside outside of the normal operational restore windows across to object storage. You can define a 0 operational restore window, but backup files still must be sealed before Veeam will offload to object storage.
I can already envisage administrators who saw the announcement for Veeam Archive Tier and have started planning the removal of their nightly tape jobs or cancelling their Cloud Connect Backup contract. Yes, it will enable them to shuffle long-term retention away from tape or CC-B, instead they can use object storage, but that’s it. They won’t be able to restore last nights backup from Cloud Tier; it’s just not designed for that purpose.
Ultimately, this new functionality is all about adding additional capacity to your scale-out backup repositories through to tiering of data into cheaper storage. Veeam has developed an intelligent way to move unique blocks into and from object storage which significantly addresses the limitations encountered in the previous Archive Tier.
By enabling the reduction of long-term retention capacity on-premises and increasing the SOBR capacity to virtually infinite is a considerable benefit for Veeam administrators, and in the typical Veeam way, it’s simple to configure as well.
**UPDATE**
Veeam have announced a ‘Copy Mode’ feature will be introduced in Veeam Backup & Replication v10, you can read more about it here https://rhyshammond.com/veeam-cloud-tier-copy-mode/
Pingback: Veeam Backup & Replication 9.5 Update 4 veröffentlicht
Great explanation of Cloud Tier. Nice work. We’ve recently successfully tested our OBS platform ActiveScale with Veeam 9.5 update 4.
Hello,
Thanks for your post
How I can restore from S3 bucket in case of a disaster (lost Veeam backup server )?
Thanks
Hey Usam,
You can add the object storage back, Veeam downloads backup files with metadata located in the object storage repository to the extents that are part of a scale-out backup repository that is being added, this is called synchronization. I recommend checking out this page on the Veeam user guide, https://helpcenter.veeam.com/docs/backup/vsphere/sync_capacity_tier_data.html?ver=95u4
It explains synchronizing Capacity Tier repositories that already contain offloaded backups.
Pingback: Veeam Cloud Tier - Copy Mode - rhyshammond.com