- Ideally, we want to minimise the amount data that needs to be uploaded to our B2 buckets because we are charged per GB each month & upload bandwidth is typically our biggest bottleneck.
- We can’t leverage Veeam built-in WAN accelerators since there is no compute available at the object storage ‘B2’ side
- Veeam currently does not have native integration with object storage so we need to rely on ‘cloud gateway’ devices such as Synology CloudSync.
- Both Synology CloudSync and Backblaze B2 offer no data deduplication, meaning if we create several full Veeam backups files to our Synology CloudSync backup repository, each Veeam full backup file will be uploaded, in full. This is in contrast to other solutions such as Microsoft StorSimple which leverages a ‘volume-container’ global block-level dedupe which means even if Veeam sends multiple full backups files to a backup repository, the StorSimple will only upload changed/unique blocks due to its block-level dedupe capability.
- The Synology CloudSync package is not aware of when the Veeam backup files are being created/modified by Veeam, this can result in files being uploaded before Veeam has finished, this happens a lot with .VBM files.
- Veeam features such as Storage-Level Corruption Guard and Defrag/Compacting the full backup file should be avoided as this results in a new full backup file being created.
With the above in mind, we need to decide whether we should configure backup job (primary backup target) or a backup copy job (secondary backup target).
Scenario 1) Backup Job
With a backup job, we would need to consider that reverse incremental should not be used, leveraging reverse incremental would result in a new full backup file being created each time the backup runs, it also creates a new reverse incremental file for the previous restore point. Meaning lots of new files that would need to be synced, this is something we are trying to avoid.
By avoiding unnecessary full backup files it will help us minimise our storage bill and importantly ease congestion on the WAN link.
Ideally, when designing our backup job, to minimise bandwidth, we should configure a forward incremental backup job with a retention period sufficient enough to meet our requirements while minimising the number of active fulls created. We can use synthetic or active fulls here, though I’d just use active full for keeping it simple.
To get started, We create a new Veeam backup job and named it appropriately.
We add the VMs that we want to protect into the backup job.
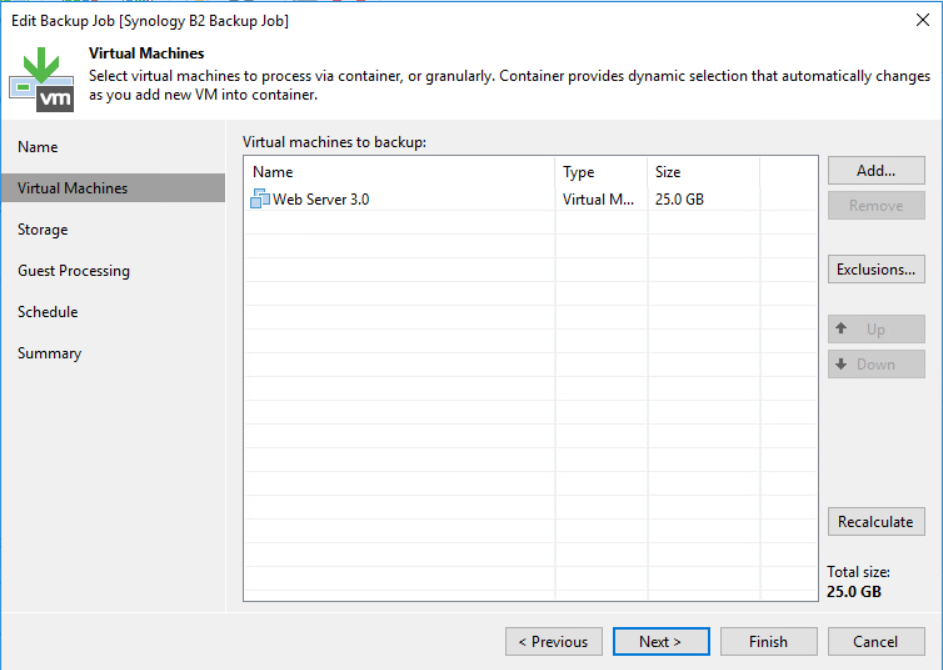
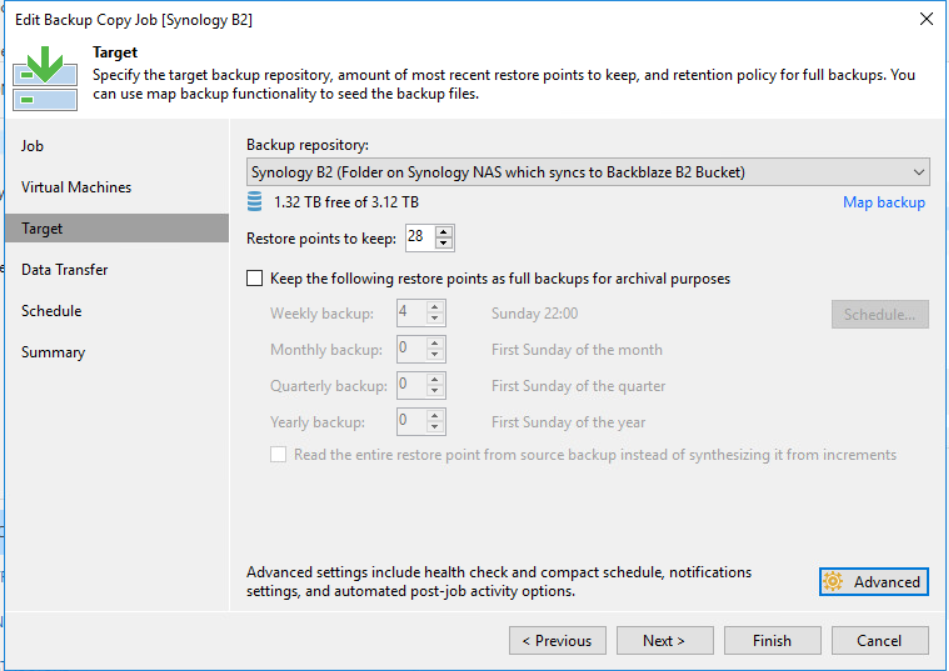
We selected the Veeam backup repository that we created earlier followed by defining the number of restore points that we require. In this instance, I’ve selected 28 restore points to keep on disk, this will enable us to meet our 4-week imaginary retention requirement.
Under ‘Advanced Settings’, we ensure that ‘incremental’ is selected and to ensure it’s not a forever incremental job we specify an active full to be created on the first Saturday of each month. I picked Saturday because the full backup file is going to be the largest file in the chain which gives it more time to be uploaded over the course of the weekend. I picked once a month to minimise the amount of data that needs to be stored in B2 and more importantly, uploaded over our WAN link.
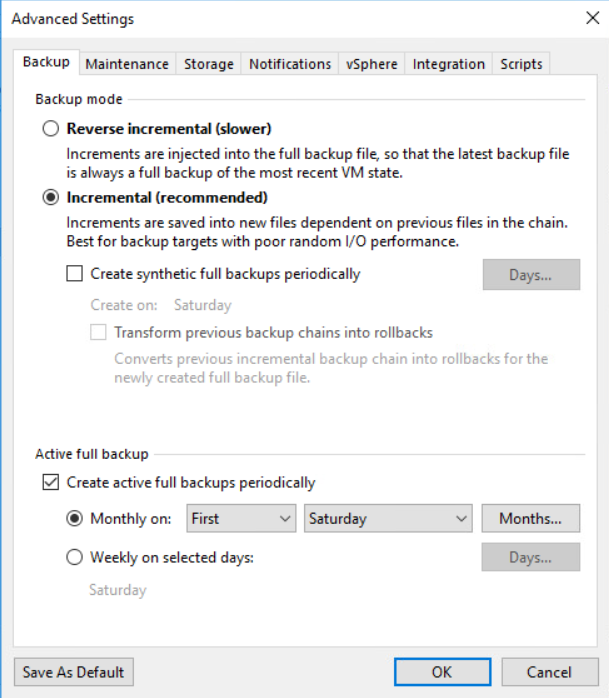
I’ve disabled all storage-level corruption guard checks and ensured that defragmentation and compaction are not enabled. We want to disable these settings as both operations result in a new backup file being created which means data that needs to be uploaded which is want we are trying to limit.

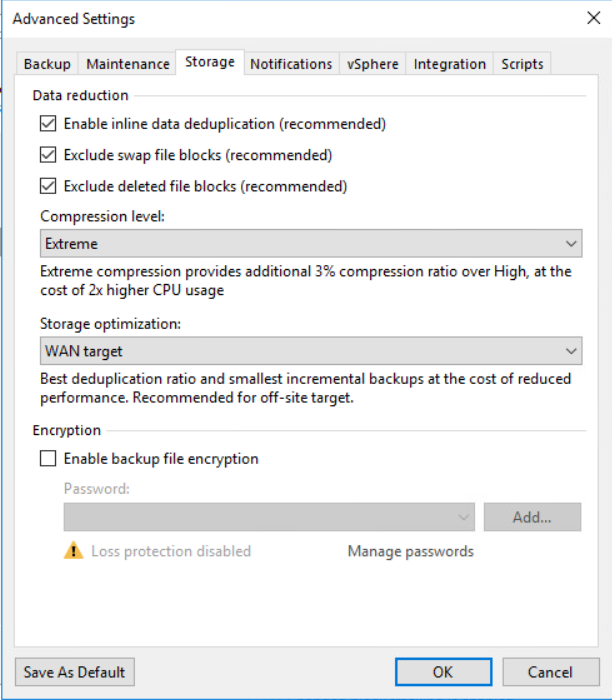
Under the next tab, Storage, We’ve enabled all data reduction options available to us in an effort to reduce our bandwidth requirements.
- Enable inline data deduplication is enabled
- Exclude swap file blocks is enabled
- Exclude deleted file blocks is enabled
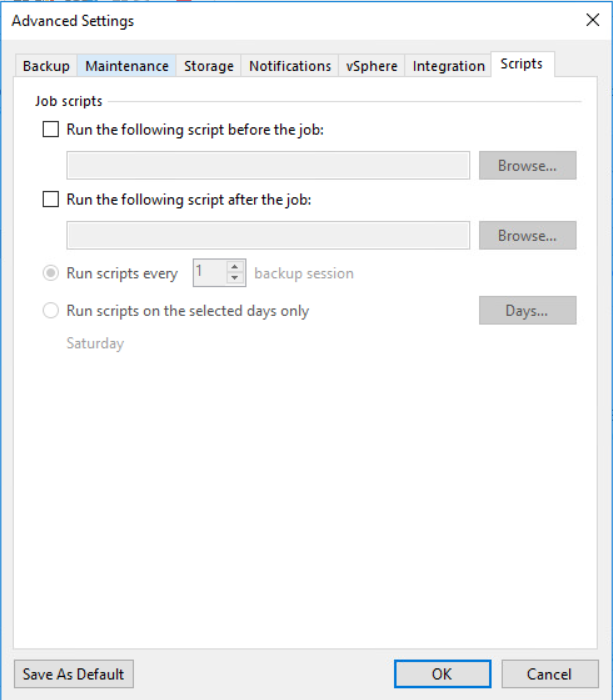
I wanted to note the job script section, specifically the ability to define a script to be executed after the job has completed. This could be an excellent way to start the sync into B2 as soon as the job has completed, this will avoid files being synced that are still in use and avoid possible wasted resources due to them being idle as a result of incorrect timing. At the time of writing I had not found a way to make this work.
Finally, we’ve configured the job schedule to start with enough time to complete before the CloudSync sync starts.

Scenario 2) Backup Copy Job
With Veeam backup copy jobs, we can create several instances of the same backup file and copy them to secondary (target) backup repositories for off-site/long-term storage. If we decided to use a backup copy job, we are forced to use the forever forward incremental method though this involves rolling the full backup file forward as the old retention points expire. What this would mean is, once we have reached the retention period and a new full backup file is synthetically created, we would need to upload an entire full backup each time the backup copy job runs. This is not ideal for organisations that don’t have fast high-speed links. Also, if you choose to go down this path you will need to look at the file lifecycle management in you B2 bucket to purge the old full backup files.

Thanks Rhys. Been wanting to do this for a while, I have all of the components to do it, apart from the time to figure it out. Now I have a great guide.. cheers..