Part 1 – Veeam Backup & Replication v10 to PureStorage FlashBlade
Authors – Lawrence Ang, Rhys Hammond and Dilupa Ranatunga
Introduction
In this blog, we’ll be configuring an NFS share on a Pure Storage FlashBlade which will be utilised by Veeam Backup & Replication v10 as an NFS backup repository.
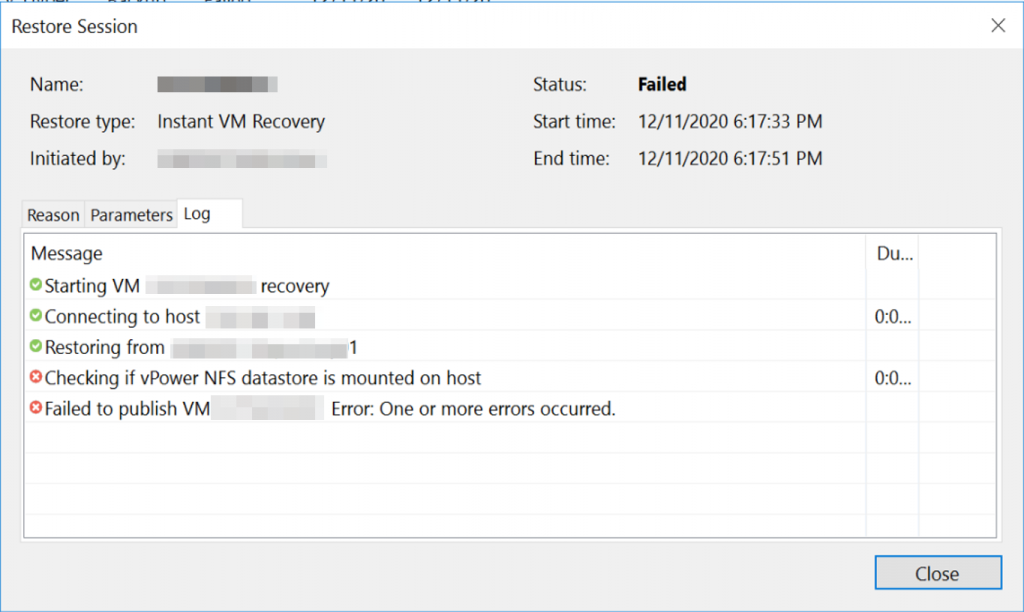
Veeam Backup & Replication has supported backups directly from NFS (Direct NFS Access) and restores directly to NFS (Data Restore in Direct NFS Access Mode) natively for a while now but backing up to an NFS share was always a bit of a challenge. Limitations around mounting an NFS share on Windows meant organisations were required to deploy workarounds that required Linux servers and NFS mount points which often ended up in the ‘too hard bucket’ for administrators who preferred the ease of Windows and SMB.
The great news is Veeam Backup & Replication v10 can now natively leverage an NFS share directly without any Linux machines acting as a middleman. In typical Veeam fashion, it’s a simple wizard-driven process to add the NFS share just like any other backup repository types supported by Veeam.

We’ll be using a Pure Storage FlashBlade as the underlying storage for the NFS share in this guide. FlashBlades are great targets for Veeam for a couple of reasons, they provide high performance in a dense form-factor, they support multiple protocols such as NFS, SMB and Object Store in parallel and scaling out is a simple case of adding another blade.
New features in Veeam v10 such as the Multi-VM Instant recovery or data APIs are increasing the storage IOPS demanded which some legacy backup storage are failing to deliver. The FlashBlade being an all-flash storage platform is designed to handle the random I/O traffic that can be generated from large Multi-VM Instant Recovery sessions (aka restore bootstorms).
With the addition of ransomware-proofing backups with PureStorage SafeMode which will be discussed in a later article in this series, it’s pretty easy to see why these devices make great Veeam backup targets.

Configuring the FlashBlade NFS Share
Let’s get started – After logging into our FlashBlade management interface, we are Lets get started – After logging into our FlashBlade management interface, we are greeted with the typical Pure Storage interface, for those familiar with FlashArrays you’ll notice the interface is identical.
Continue reading →