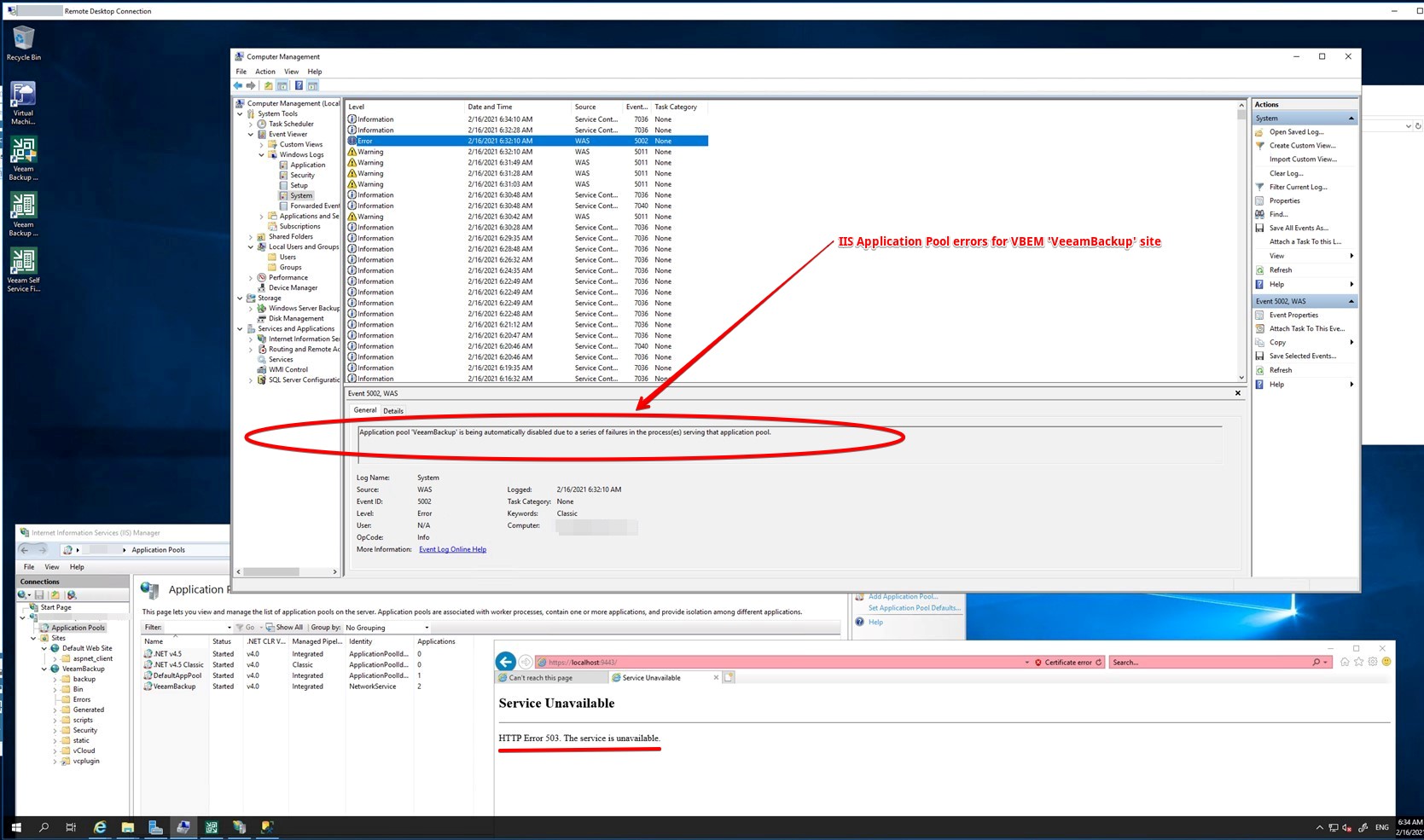
I was recently involved with a Veeam deployment that was running into problems during testing, their only performance tier had run out of space. Though this wasn’t unexpected as the disk provisioned was undersized and just temporary until testing was finished, it was preventing new backups from finishing successfully.
The full performance tier belonged to a Scale-Out Backup Repository that was also configured with a capacity tier (copy + move mode) backed by an immutable AWS S3 bucket. Worth mentioning those backup files in the capacity tier were still within the immutability retention period.
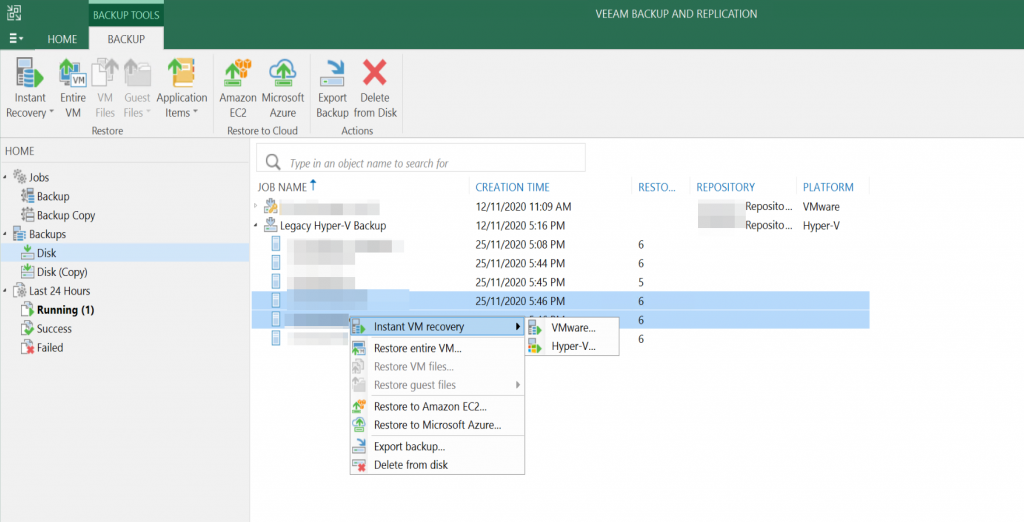
According to the user guide “If you use the scale-out backup repository, keep in mind that the Delete from disk operation will remove the backups not only from the performance tier but also from the capacity and archive tier. If you want to remove backups from the performance tier only, you should move those backups to the capacity tier instead. For details, see Moving to Capacity Tier.”
Attempting to perform a “Delete from disk” operation was failing with the error “Error: Unable to delete backup in the Capacity Tier because it is immutable”.
Continue reading