Recently I had the opportunity to deploy Veeam B&R utilising Cloud Connect Replication for a customer to replace their existing DR solution. We were running into an issue with a couple replication jobs that were sitting at 99% for longer than I would expect, in some cases for several hours.
I wasn’t sure what it was doing as there was no network traffic, CPU or even disk usage on the on the source that could be detected. The Veeam job showed no tasks currently underway and I didn’t want to speak to the Service Provider to check their end until I had verified everything was working as expected at the source so I kept digging.
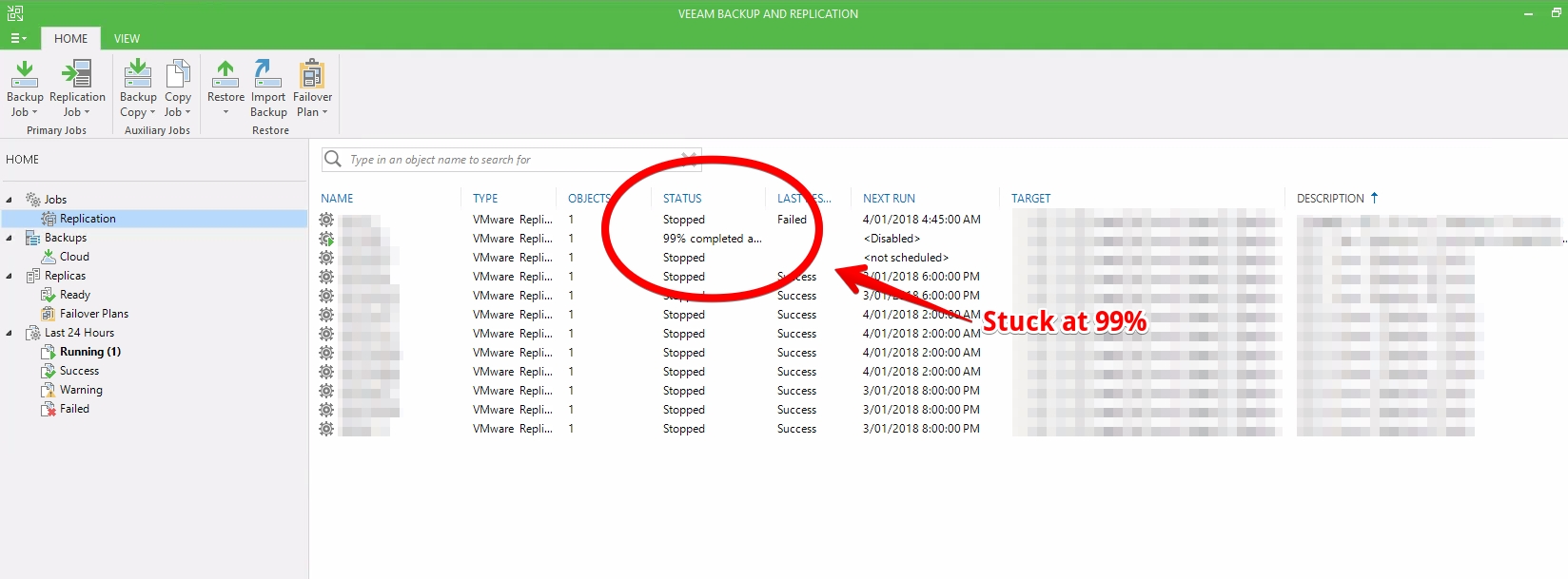
Examing the job in question shows the below,
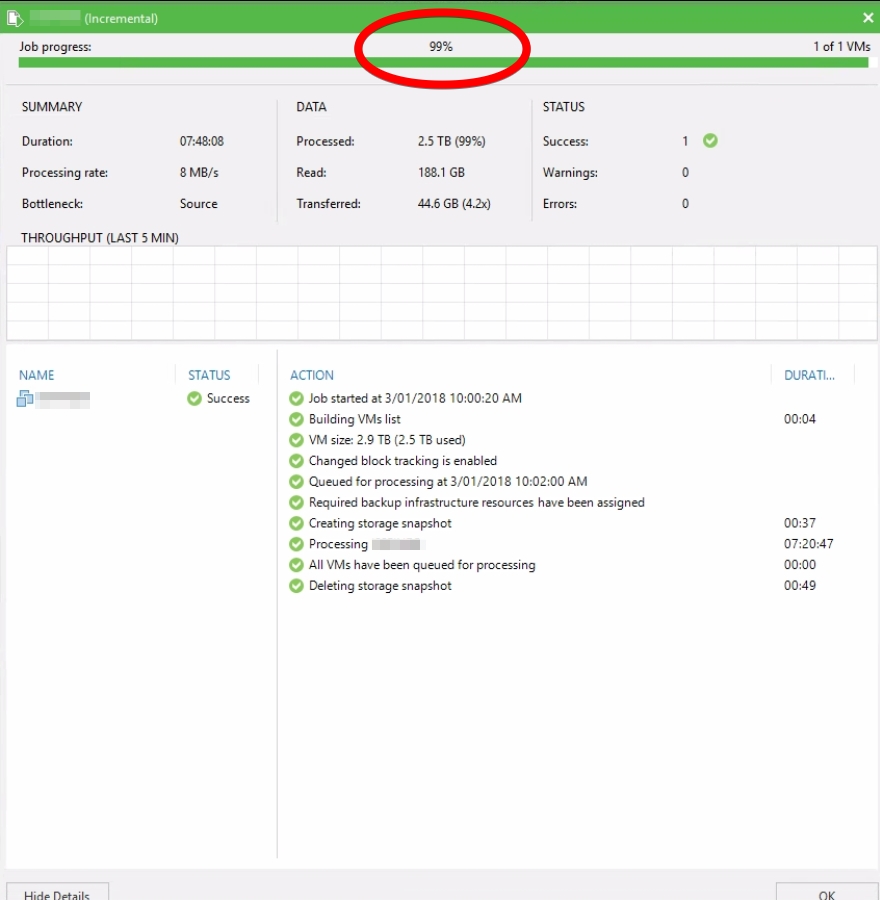
Selecting the VM brings up the following,
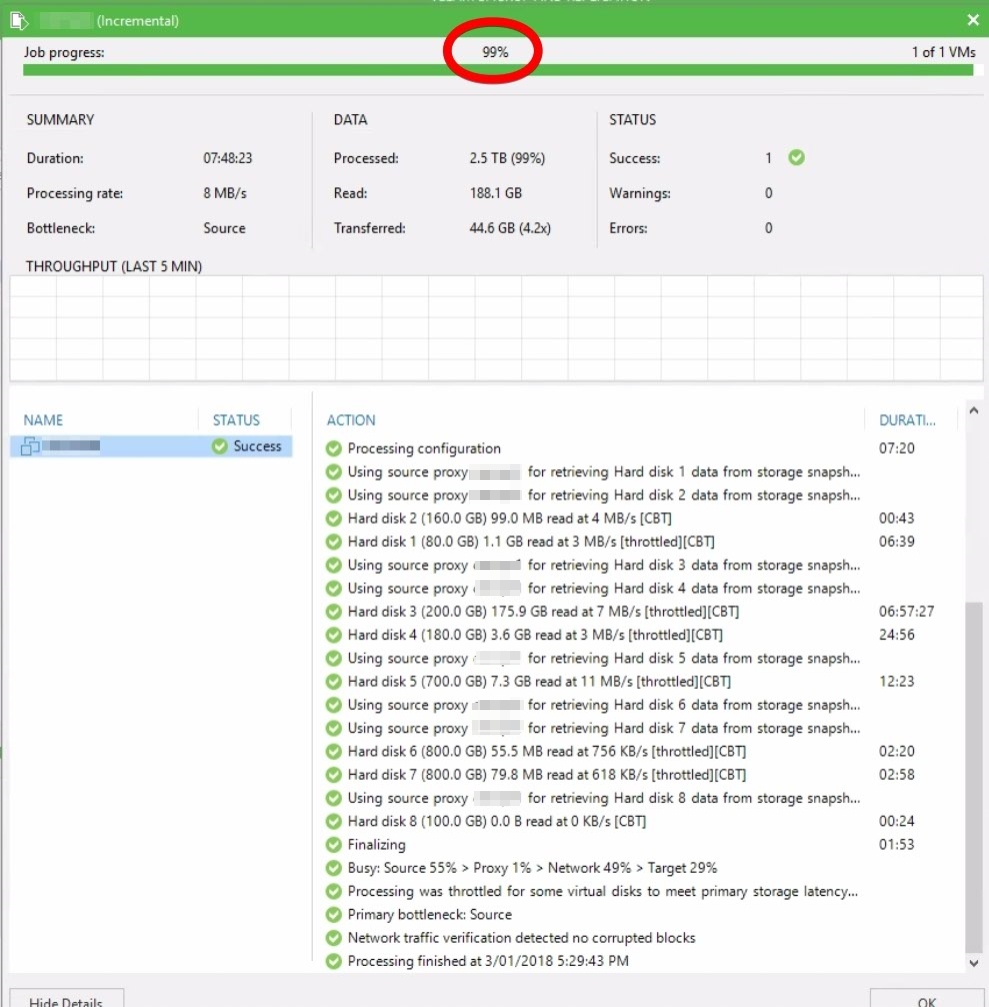
So everything looked happy except for the 99% part. Was it a UI bug, refreshing the console with ‘F5’ didn’t fix the issue.
Having a closer look at the replicas section though I found that the VM in question was still processing. A quick check with the Service Provider to verify on their end confirmed that snapshots were still being committed on their end for the VM in question.
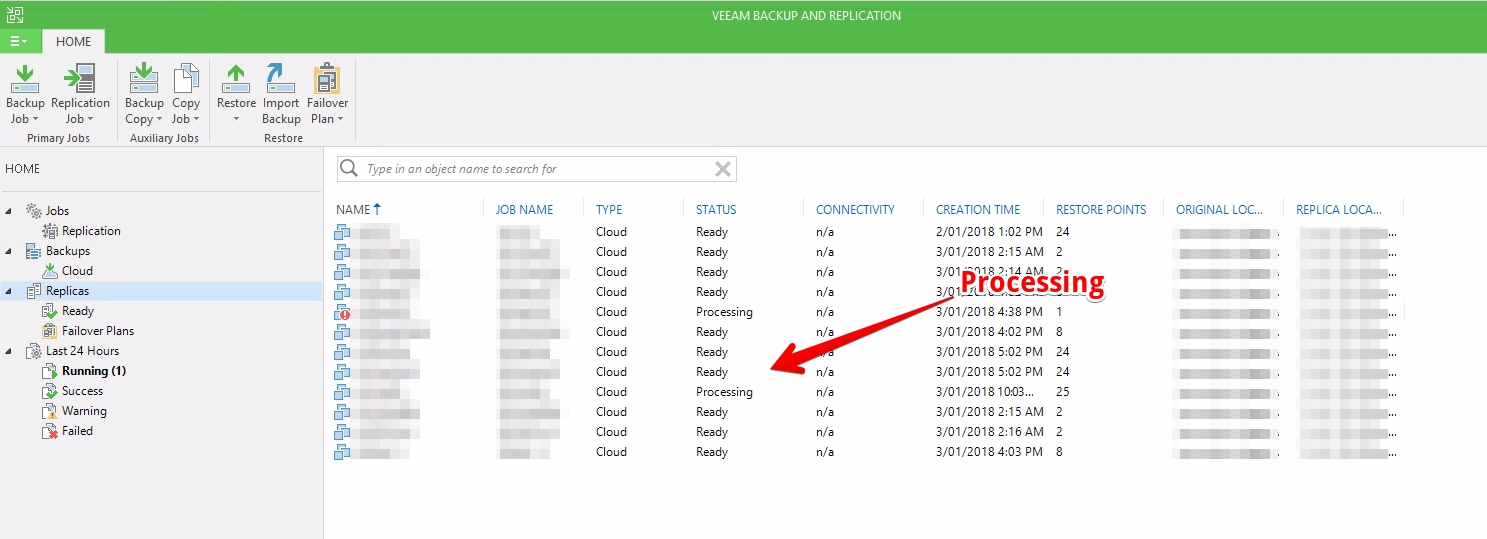
So it turned the 99% issue was just the target ESXi host processing the retention policy (VM snapshot commit). The thing to remember is that highly transaction VMs will take longer to commit the snapshot on the replica side and this particular VM was a large highly transactional database.
I’m going to investigate if anything can be done about improving this snapshot commit process. I would expect that reducing the retention, therefore, the number of snapshots would be a good place to start. Additionally, we can consider moving the VM replica to a faster tier of storage.
Did you get this any faster? I have a 1.27TB sql database that takes ages to commit the snapshots – its only has two snapshots
Unfortunately, the snapshots being committed were on the cloud connect service provider side so being on the tenant side we had very limited control over it. A snapshot commit that takes longer than normal can be caused by underperforming storage and/or larger than normal changes occurring during the backup/replication job.
Thanks for the article. I noticed the same thing tonight while doing a migration to a new farm at a datacentre. The, easiest way to assess how much time left for completion is to browse the datastore files on the target where the VM replica resides. Then check the sizes of the deltas (eg server_1-000001.vmdk) vs the base (server_1.vmdk). Hit the vCenter refresh button at the top, you’ll see the base file increase as the delta is written too it, take a note of the current time, then refresh the screen in say 10 minutes time and take a note of the new size, multiple the difference by 6 and that’ll give you the number of TB per hour the storage is capable of committing at. Then work backwards to determine roughly how much time left. I’m currently waiting for a 1TB+ file to commit, it’s doing around 215GB per hour. So with a difference of 450GB between base and delta, a little over 2 hours to go!